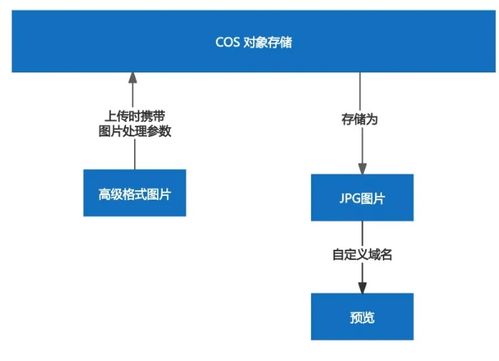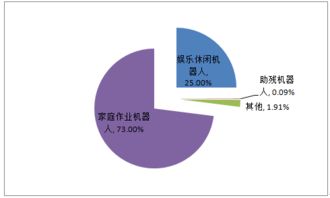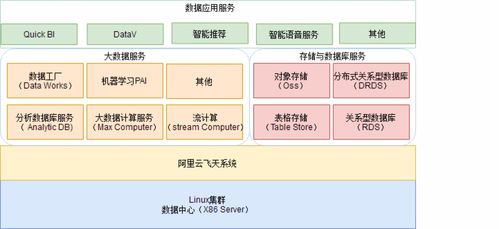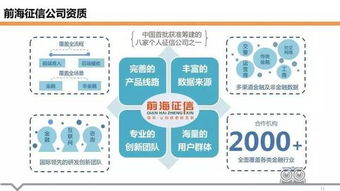
在当今数据驱动的时代,数据科学家已成为各行各业炙手可热的职业。作为一名资深数据科学家,我想分享我的成长历程,特别是关于数据处理服务的经验和见解。
起步阶段:打好基础
我的数据科学之旅始于对数学和编程的热爱。大学期间,我系统学习了统计学、线性代数和概率论,同时掌握了Python、R等编程语言。这个阶段,我认识到数据处理是数据科学的基础——没有高质量的数据,再复杂的模型也难以产生价值。
初级阶段:掌握数据处理核心技能
进入职场后,我开始接触真实世界的数据。这个阶段,我重点学习了:
- 数据清洗与预处理:处理缺失值、异常值,进行数据标准化
- 数据集成与转换:整合多源数据,进行特征工程
- 数据存储与管理:熟悉SQL、NoSQL数据库,理解数据仓库概念
中级阶段:构建数据处理服务体系
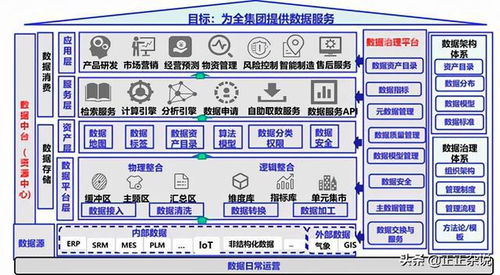
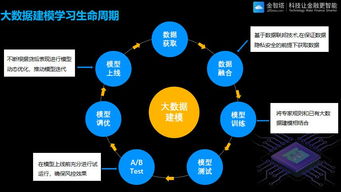
随着经验积累,我开始从单点技术转向构建完整的数据处理服务体系:
数据采集服务
建立自动化的数据采集管道,从API、数据库、日志文件等多渠道获取数据
数据清洗服务
开发标准化的数据清洗流程,确保数据质量和一致性
特征工程服务
构建可复用的特征工程框架,为机器学习模型提供优质输入
数据监控服务
实现数据质量监控和异常检测,及时发现并处理数据问题
高级阶段:数据处理的战略价值
如今,我的工作重点已转向:
数据治理与标准化:建立企业级数据标准和治理框架
自动化数据处理流水线:构建端到端的自动化数据处理系统
数据服务化:将数据处理能力封装为API服务,赋能业务部门
数据安全与合规:确保数据处理符合隐私保护和法规要求
核心经验分享
- 工具只是手段:不要过分追逐新技术,而是要理解数据处理的核心原理
- 业务理解是关键:只有深刻理解业务需求,才能提供有价值的数据处理服务
- 持续学习:数据领域技术更新迅速,保持学习心态至关重要
- 沟通协作:数据科学家需要与业务、产品、工程等多方协作
数据处理服务是数据科学的基础,也是价值创造的起点。希望我的成长历程能为正在这条道路上的同行提供一些启发和参考。